What I Learned About How LLMs Work
📌 Credit: This post is my personal learning summary based on Andrej Karpathy's talk — Intro to Large Language Models (YouTube, 2023) and his follow-up State of GPT (Microsoft Build, 2023). All core concepts originate from his work. The System 1 / System 2 framework comes from Daniel Kahneman's book Thinking, Fast and Slow (2011).

The 3 Phases of Building an LLM
Here is the complete pipeline from raw internet data to the ChatGPT or Claude you use every day:
RAW INTERNET DATA (100TB+)
↓
[ Phase 1: Pretraining ] ← weeks of GPU compute, $10M–$100M cost
↓
BASE MODEL ← knows everything, follows nobody
↓
[ Phase 2: Fine-Tuning ] ← human-written Q&A examples
↓
SFT MODEL ← answers questions, but can still be harmful
↓
[ Phase 3: RLHF ] ← human preference rankings
↓
ASSISTANT MODEL ← ChatGPT, Claude, Gemini
Phase 1 — Pretraining (The Base Model)

The internet is crawled — Wikipedia, books, GitHub, Reddit, Stack Overflow — everything gets cleaned and compressed into GPU/TPU compute clusters. The model does one thing only:
Predict the next token.
That's it. Billions of parameters adjust themselves over weeks to get better at this single task. After compute costing tens of millions of dollars, you get a base model.
A base model is not a chatbot. It's a document completer. Ask it a question and it might just continue writing more questions instead of answering — because that's what "the next token" looks like statistically.
💡 Key insight: The model is a lossy compression of the internet. 100TB of text → ~100GB of floating-point numbers (weights). It doesn't store facts like a database — it reconstructs them from patterns.
Phase 2 — Supervised Fine-Tuning (SFT)
Human contractors write thousands of high-quality question-answer pairs:
Q: "What is the capital of France?"
A: "The capital of France is Paris."
Q: "Explain recursion to a 10-year-old."
A: "Imagine you're looking for your keys..."
The model trains on these examples to learn the format of being helpful — how to structure an answer, not just how to complete arbitrary text. The result is an SFT model — better, but still capable of generating harmful or incorrect responses confidently.
Phase 3 — RLHF (Reinforcement Learning from Human Feedback)
This is the step I initially missed — and it's arguably the most important one.

How it works:
- The model generates two different responses to the same prompt
- Human raters choose which response is better
- A separate Reward Model is trained on thousands of these comparisons
- The main LLM is then trained using Reinforcement Learning to maximize the reward score
- Result: a model that is helpful, harmless, and honest
This is what made ChatGPT feel so different from everything before it. Before RLHF, language models existed — after RLHF, assistants existed.
📌 Credit: RLHF was popularised in the context of LLMs by OpenAI's InstructGPT paper (2022) — Ouyang et al. Anthropic's variant using AI feedback instead of human feedback is called RLAIF.
Tokens, Not Words
The model doesn't see words — it sees tokens, which are chunks of roughly 3–4 characters each.
Input: "unhappiness"
Tokens: [ "un" | "hap" | "pi" | "ness" ]
Count: 1 2 3 4 = 4 tokens
Here are more examples:
"Hello world" → ["Hello", " world"] = 2 tokens
"ChatGPT is amazing" → ["Chat", "G", "PT", " is", ...] = 5 tokens
"日本語" → ["日", "本", "語"] = 3 tokens
Why this matters for you as a builder:
| What | Impact |
|---|---|
| API pricing | Charged per token, not per word |
| Context window | Limits in tokens (128K tokens ≈ ~90K words) |
| Weird failures | Model can't reliably count letters — it never sees individual characters |
🔧 Try it yourself: Play with OpenAI's free Tokenizer tool to see how any text gets split into tokens in real time.
System 1 vs System 2 Thinking
📌 Credit: The System 1 / System 2 framework comes from Nobel laureate Daniel Kahneman's book Thinking, Fast and Slow (2011). Andrej Karpathy applies this framework to LLMs in his talks.
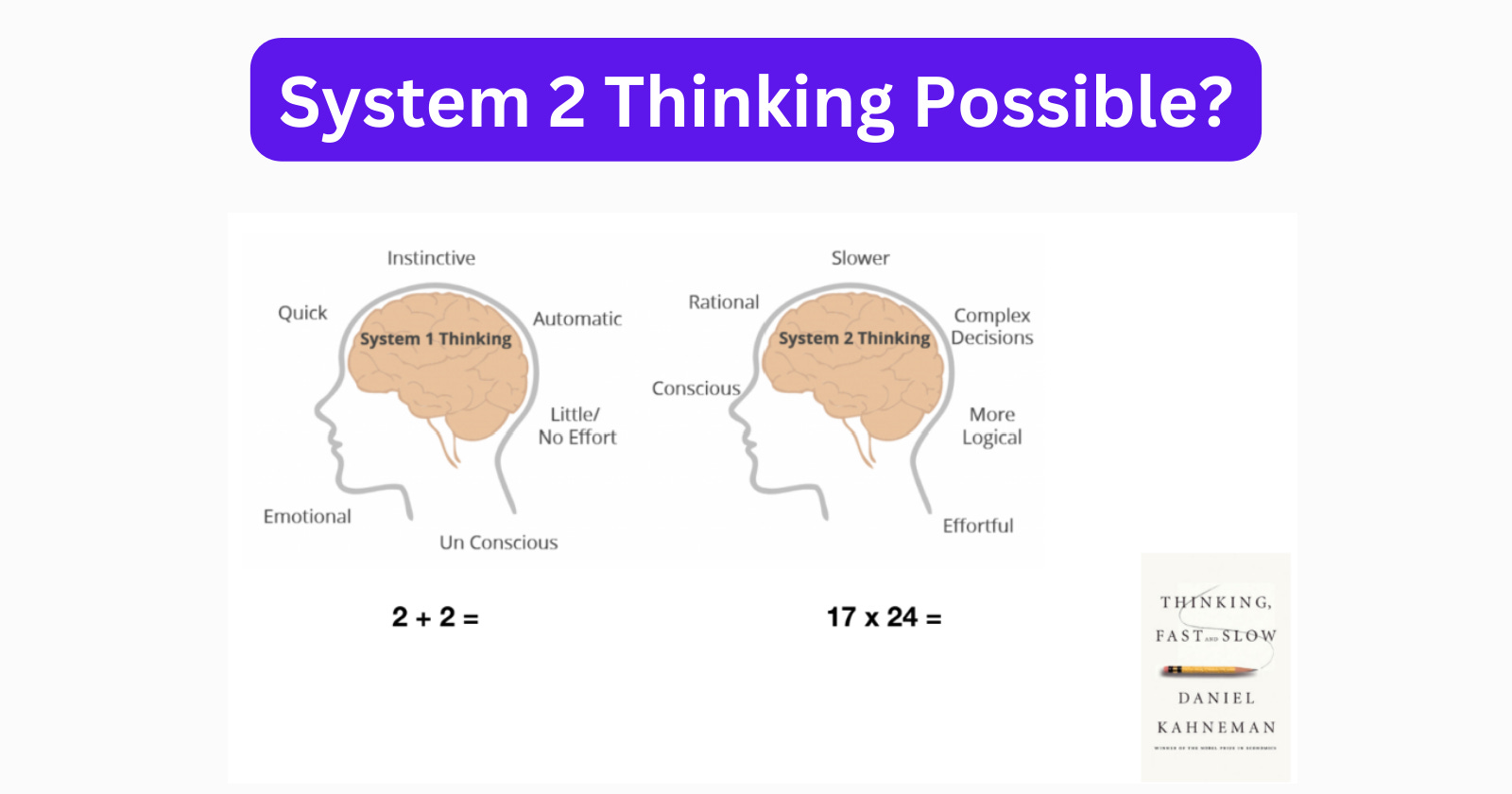 System 1 (fast, instinctive) vs System 2 (slow, deliberate) applied to LLMs. Image credit: Zahiruddin Tavargere — The Adaptive Engineer
System 1 (fast, instinctive) vs System 2 (slow, deliberate) applied to LLMs. Image credit: Zahiruddin Tavargere — The Adaptive Engineer
| System 1 | System 2 | |
|---|---|---|
| Speed | Instant | Slow, deliberate |
| Nature | Pattern-matching | Step-by-step reasoning |
| Human example | Recognising a face | Solving a chess problem |
| LLM equivalent | Single forward pass → answer | Reasoning models (o3, R1) |
Most LLMs today are System 1. A single forward pass through the neural network generates the next token — no backtracking, no verification, no "let me check that."
The industry is actively building System 2 capability into models:
- OpenAI o3 / o4 — inference-time compute, internal reasoning traces
- DeepSeek R1 — open-source reasoning model trained with RL
- Gemini 2.5 Pro Deep Think — extended thinking mode
Why RAG Exists
Since the model is a frozen compression of past training data, it has hard limitations:
❌ Doesn't know about events after its training cutoff
❌ Doesn't know your private documents or company data
❌ Can't look things up — it reconstructs from learned patterns
❌ Will confidently "hallucinate" when it doesn't know something
RAG (Retrieval-Augmented Generation) solves this:

User question
↓
Convert to embedding (vector)
↓
Search vector database for similar document chunks
↓
Inject retrieved chunks into the prompt as context
↓
LLM answers using real, specific, up-to-date information
That's why my next project is building a RAG chatbot that can answer questions from my own documents. 🚀
What I Initially Got Wrong
When I first summarised my understanding, I had ~75% of the picture. Here's what I missed:
| Concept | Status |
|---|---|
| Pretraining on internet data | ✅ Had it |
| Fine-tuning for Q&A | ✅ Had it |
| System 1 thinking dominance | ✅ Had it |
| RLHF | ❌ Missed — the most important step |
| Tokens vs words | ❌ Missed — critical for building |
| Model as lossy compression | ❌ Missed — core mental model |
This is exactly why learning in public is valuable — articulating what you know reveals what you don't.
Key Takeaway
An LLM is not a database. It is not a search engine. It is a lossy compression of human knowledge, decompressed on demand via a query. RLHF is what turns that compression into a useful assistant. RAG is what gives it access to knowledge it was never trained on.
Resources & Credits
| Resource | Author | Link |
|---|---|---|
| Intro to Large Language Models (video) | Andrej Karpathy | YouTube |
| State of GPT (video) | Andrej Karpathy | YouTube |
| Thinking, Fast and Slow (book) | Daniel Kahneman | Wikipedia |
| InstructGPT paper (RLHF) | Ouyang et al., OpenAI | arXiv |
| OpenAI Tokenizer tool | OpenAI | platform.openai.com/tokenizer |
| LangChain for LLM App Dev (course) | DeepLearning.AI | deeplearning.ai |
This is part of my 6-month journey from full-stack developer to AI-native engineer. Follow along on GitHub and LinkedIn.